Here’s where cloud computing and Presto can help.
What Is Presto?
Presto has the advantage of being open-source, which means it is updated regularly and developers contribute to it often. The Presto platform works with non-relational data sources like: And relational databases like:
MySpacePostgresSQL andMS SQL Server
With Presto, you can query data wherever it is stored. That means you don’t need to transfer the data into a relational database or data warehouse. Presto was created for SQL and supports standard SQL semantics. This includes sub-queries, complex queries, outer joins, distinct counts, and approximate percentiles. Executing queries is also faster, as it runs parallel to a memory-based architecture. Therefore, you don’t have to worry anymore about how long it could take to query a massive database. The results come back in seconds. Learn how to deploy Presto and its architecture on their documentation. Also Read: How To Update Device Drivers on Windows 10? {Simple Guide}
Key Concepts
Key SQL concepts are widely known. To understand how Presto works, we first need to understand its core concepts.
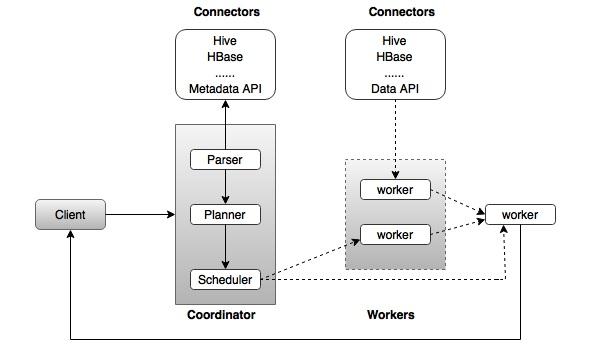
Server types
Presto uses two server types: the coordinator server and the worker server. The worker nodes process the queries, fetching data from the connectors. The coordinator fetches the results and sends them to the client. Coordinator servers also parse statements and manage nodes. It works similar to Massive Parallel Processing database management systems. Image Source: tutorialspoint Also Read: How to Update Drivers on Windows 10,8,7 – Update Device Drivers
How Presto processes queries?
When presto receives a query, it executes it by breaking it into multiple stages. Typically the system creates a root stage and related stages. The stages are then distributed into tasks across the worker nodes.
Advantages of using Presto
Presto is becoming very popular with large enterprises like Netflix, Facebook, Atlassian, and Airbnb. For instance, Facebook uses Presto to process one petabyte of data every day, running over 30k queries. Presto includes two separate open-source projects: PrestoSQL (now called Trino) and PrestoDB. It is very popular for a wide array of use cases, across different types of data lakes and data warehouses. Let’s look at some of the advantages that make Presto so popular.
1. Easy integration
One of the key advantages of Presto is that it integrates with your existing data system without needing modifications. Therefore, by adding Presto you add fast analytics capabilities without needing to tweak your existing system.
2. Faster performance
One of the reasons Presto was developed was because the existing Apache Hive didn’t perform well with interactive queries. Presto is designed to handle interactive BI queries. Besides, it follows the push model, processing a SQL query using multiple stages concurrently, meaning all stages are pipelined without waiting between stages. Presto also has memory-to-memory data transfer, without the need to write data to disk, enhancing performance.
3. Designed for the cloud
Presto runs storage and computes separately, which makes it very suitable for cloud environments. Companies using PrestoSQL can easily scale up or down depending on the load without causing data loss. This can happen because the Presto cluster doesn’t store any data.
4. Unified SQL interface
SQL is the most popular language for data analytics. Data scientists, analysts, and engineers use SQL for processing, analyzing, and testing data, integrating it with business intelligence tools. Presto has the ability not only to query data from SQL sources but also from NoSQL databases like Elasticsearch and Cassandra. It supports ANSI-SQL and Postgres connectivity. This gives Presto a versatility that other distributed systems don’t have. The interface is ideal for medium-sized data because it has the same Window functions that PostgreSQL has. Also Read: How To Update Graphics Drivers In Windows 10 {Simple Guide}
What can you use Presto for?
Presto is used across industries for a wide variety of use cases. It is especially suitable for ad-hoc and interactive queries. Let’s explore some common use cases:
Data lake analytics
You can use PrestoSQL to query data on a data lake without needing to transform the data. Presto allows you to query data where it sits. Therefore, you can use it to empower your data lake analytics by querying structured and unstructured data.
Ad hoc querying
Presto allows you to run queries anytime regardless of where your data resides. Even better, with Presto connectors, your teams can access datasets in a wide range of data sources, and since queries are run in seconds instead of hours, your system performs faster.
Batch ETL
Instead of using legacy batch processing systems, you can use Presto to run queries that are efficient on resources. You can aggregate data from multiple data sources and conduct high-throughput queries. In summary, Presto has several advantages for companies that need to process large amounts of data, conduct ad hoc, interactive queries, and run analytics from disparate data sources.